苏黎世联邦理工学院研究通过12个小型无线电磁传感器追踪人体姿态
2021-10-13
苏黎世联邦理工学院的先进交互技术实验室(Advanced Interactive Technologies;AIT)专注于而研究机器学习、计算机视觉和人机交互的交叉融合。团队的主要任务是开发人类与复杂交互系统互的新方法,比如说计算机、可穿戴设备和机器人。
日前,AIT实验室撰文介绍了一个面向AR/VR的定制电磁传感系统,通过12个小型无线电磁传感器来追踪人体姿态。下面是映维网的整理:
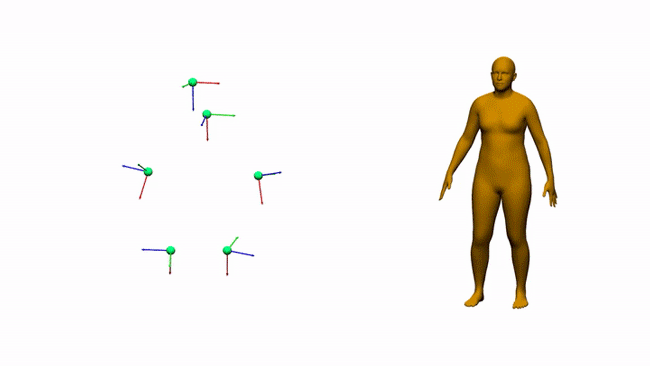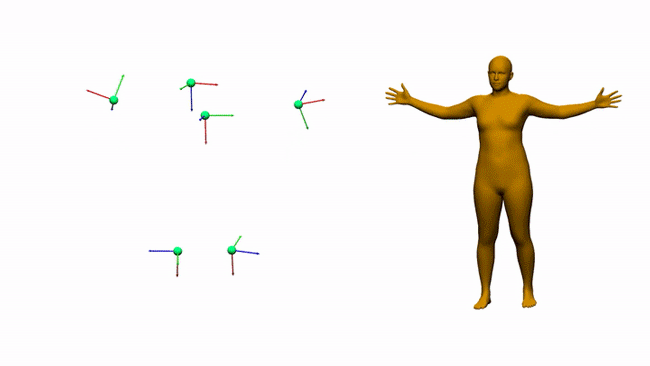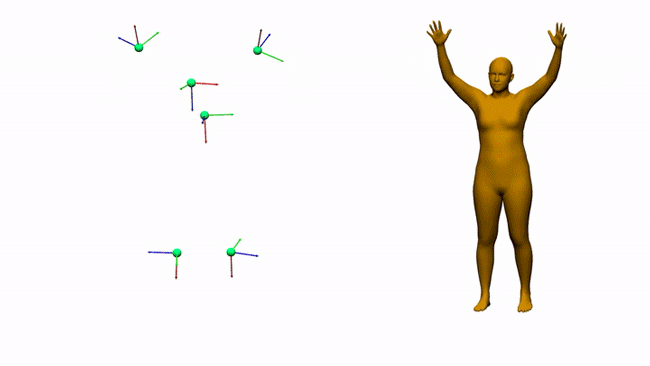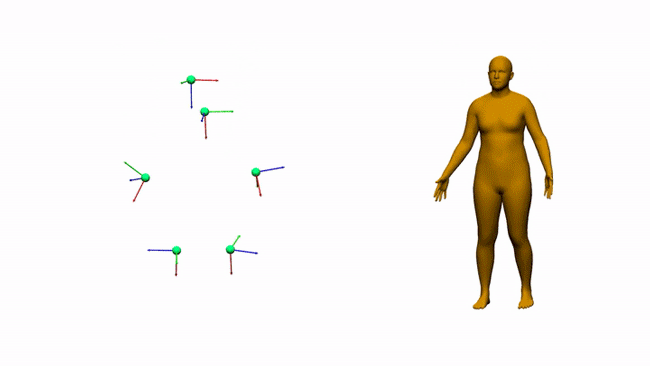
AIT实验室通过6个电磁测量估计三维人体姿态和形状
对于娱乐、通信、医疗和远程显示等领域,AR和VR是一个富有前景的计算平台。沉浸式AR/VR体验的一个重要组成环节是精确重建用户全身姿态的方法。尽管消费者传感器的姿态估计在近几年取得了令人印象深刻的进展,但对外部摄像头的需求固有地限制了用户的移动性。身戴式传感器(附接到身体/由身体穿戴的传感器)则有望避免这一限制,但它同时存在自身的挑战。我们在这个项目中研究了基于电磁(EM)的追踪传感技术,用6-12个没有Line-of-Sight(LOS)视线限制的定制无线EM传感器来进行人体追踪。
1. EM传感原理
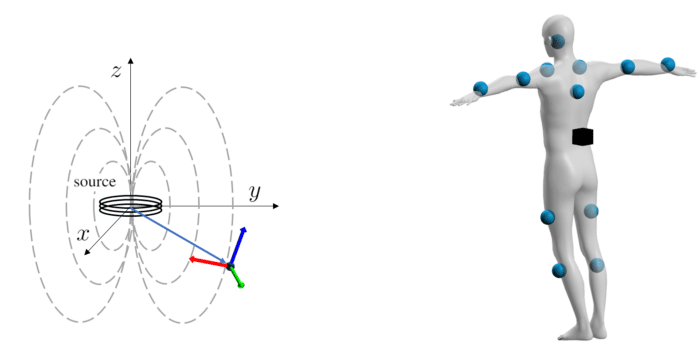
(左)由发射源发射的电磁场,其中发射源由传感器定位其位置和方向;(右)在用户身体放置电磁源(黑色立方体)和无线电磁传感器(蓝色球体)
EM追踪技术/基于EM的追踪技术已经存在一段时间。早期的军事应用可追溯到20世纪60年代。在电磁感应中,发射源发射电磁场,其中传感器可以确定其相对于发射源的位置和方向。市场拥有大量的EM追踪系统,而它们在追踪范围、更新率和硬件形状参数方面不尽相同。我们发现现有的解决方案并不适合我们研究的特定用例(全身追踪),因为它们要么涉及大型传感器,要么使用妨碍移动的系留传感器。所以,我们开发了一个搭载12个小型无线EM传感器的定制版EM追踪系统。所述传感器经过调整,可在发射源周围0.3–1米范围内工作。这允许我们在人体附接多达12个传感器,如上图所示。
在一个典型的场景中,我们发现与光学标记追踪(Optitrack)相比,单个传感器的精度通常在1 cm位置和2–3度角误差范围内。但与光学标记追踪相比,我们的EM传感器没有LOS视线限制。
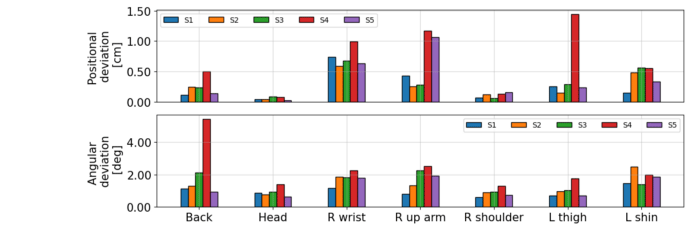
针对7个选定传感器位置和5个不同用户(S1-S5),EM追踪和光学标记追踪之间的比较。
2. 任务
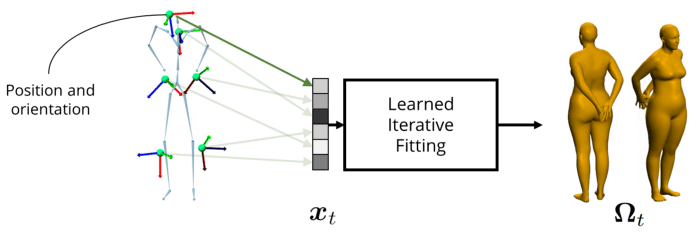
要设计包含多达12个小型、无线且时间同步的传感器的EM追踪系统本身就是一个挑战,而我们同时需要解决如何从EM测量中重建身体姿态和形状的问题。这是我们正在研究的任务。具体地说,给定n个位置和方向测量值(加起来为x),我们希望找到一个将所述输入映射到身体姿态和形状的函数,亦即SMPL参数,表示为Omega。
这非常具有挑战性,原因有几个。第一,尽管电磁感应可以非常精确,但传感器的精度取决于其与发射源的距离。在我们的例子中,这意味着我们的输入测量与姿态相关。
第二,理想情况下,我们希望尽可能少地为人体穿戴仪器,并将传感器数量减少一半,只需在前臂、小腿、上背和头部使用6个传感器。但这会令身体姿态欠约束,例如无法直接观察到左上臂的运动。所以,由其产生的方法需要能够根据简化的传感器组来推断未观察到的关节。
第三,当我们安装传感器时,传感器与皮肤之间的偏移量会因用户而异。另外,由于EM传感器的姿态依赖精度,以及传感器在运动过程中可能会无意中滑落,偏移会随时间而变化。所以,所提出的方法应该要对所述变化具有鲁棒性,以便我们可以为多人3D姿态和形状估计提供单一模型。
这就是我们选择Learned Iterative Fitting(学习迭代拟合)的原因,它是基于学习和优化方法的混合。Learing学习帮助我们利用强大的姿态先验来解决上述挑战,而Iterative迭代优化则允许提高预测的准确性。下面我们将详细地解释工作原理。
3. Learned Iterative Fitting(学习迭代拟合)
为了从6–12个EM测量值x估计SMPL姿态和形状,我们采用了最近提出的Learned Gradient Descent(LGD;学习梯度下降) 框架。在LGD中,我们首先定义重建损失,而我们的目标是最小化:
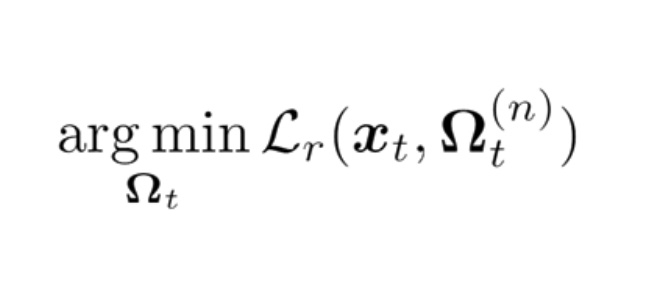
这个损失测量能在多大程度从SMPL姿态和形状的当前估计值重建输入x。为了实现这种重建损失,我们定义了一个在给定Omega时计算虚拟EM测量值的函数。
LGD采用Per-Parameter更新规则,通过神经网络N估计梯度,而不是以传统方式最小化重建损失。
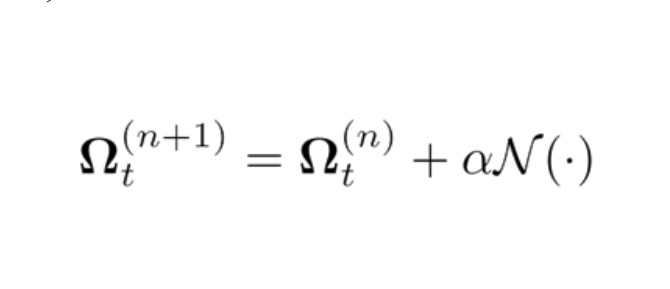
这允许在典型的4次迭代中快速收敛。为了提供Omega的初始估计,我们将输入馈送到RNN。所以,我们的方法的完整概述如下。
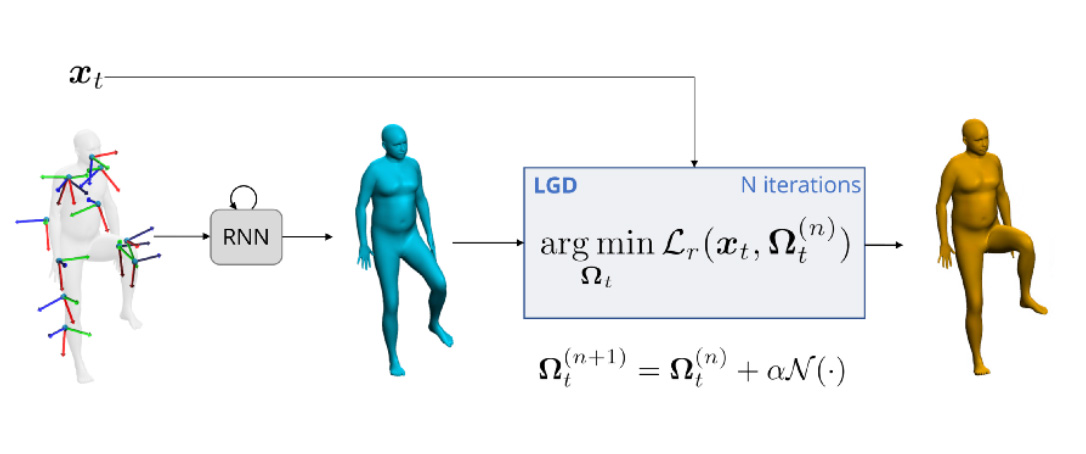
为了利用LGD,我们必须训练神经网络N。这需要一个将EM测量与SMPL姿态配对的大规模数据集,亦即意味着昂贵的获取成本。相反,我们捕获一个较小的真实数据集用于评估目的,并使用AMASS合成虚拟EM测量(使用它来训练N)。通过从专用真实校准序列中提取用户特定的皮肤到传感器偏移,我们可以通过这样一种方式来扩充训练数据,即最终的模型可以很好地泛化到多个被试,不需要进一步的域适应技术。
4. 新捕获的数据集
如上所述,我们捕获了一个由成对的EM测量和SMPL姿态组成的新数据集来评估我们的方法。所述数据集包含大约37分钟的运动(约66k帧),涉及3名女性和2名男性被试。为了获取SMPL参数,我们在离线多阶段优化过程中使用来自4个Azure Kinect的RGB-D数据。记录的动作类型包括手臂运动、弓步、下蹲、跳高、就坐和四处走动等。所述数据以后将提供下载。更多详细信息请访问我们的项目页面。
5. 结果
为了评估我们的方法,我们训练了两个模型:一个使用6个传感器作为输入;另一个使用完整的12个传感器设置。实验发现,基于混合LGD的方法优于基于纯学习和纯优化的方法。这突出了LGD的优点:它提供了准确的姿态估计,而与纯优化相比,它在推理时可以快几个数量级。
在12个传感器的输入下,我们实现了低至31.8毫米或13.3度的重建误差。当使用精简的6传感器组件时,性能会下降到35.4毫米或14.9度,但依然具有非常强的竞争力。
实验结果可以参阅下面这个补充性视频:

VR头显真的需要到180Hz吗?
2020-05-13

全球首次!圆周率科技5G+VR直播带你“云登顶”世界屋脊
2020-05-28

前HTC CEO周永明发布了一体式VR头显Mova
2020-05-27

数字化虚拟景区:未来必然趋势
2020-05-15

iPad Pro:HoloLens 2第三人称视角的最佳解决方案
2020-05-13